
- 1) HBase 란?
- HDFS를 저장소로 사용하는 CF 계열의 NoSQL 데이터베이스.


https://www.edureka.co/blog/overview-of-hbase-storage-architecture - HMaster : HRegionServer 의 모니터링을 담당함.
- RegionServer : 데이터를 분산저장하는 기능을 수행함.
- Region(영역) : (정렬된 연속적인 데이터를 저장한) '큰 테이블' 을 분산 시키기 위해, (RowKey 범위로) 나누는 단위.
- Meta Region : 각각의 Region 이 보유하는 'RowKey 범위' 를 기록하는 곳.
- Root Region : 'Meta Region' 의 위치를 기록 하는 곳.
- 즉, Root > Meta > Region 이 트리-계층적으로 정보를 저장하게 됨.
- (한 Region이 일정 커지면~ 두 Region으로 스플릿 됨! Like B-Tree?)
- HDFS : 실저장소. (데이터의 저장 및 복제)
- Zookeeper : HMaster 노드정보 유지 및 (장애시) 마스터 재선출 담당.

https://cyberx.tistory.com/164 - ...
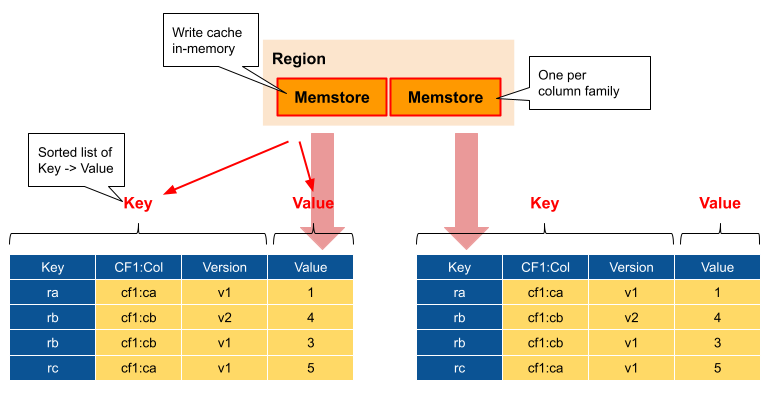
- Write 방식
- 일단, WAL(Write Ahead Log) 에 데이터를 저장. (RDB의 CommitLog 와 유사함)
- zookeeper 가 저장 가능한 RegionServer 의 이벤트 감지 -> WAL 데이터 -> Memstore 저장
- zookeeper 가 Memstore 가득찬 이벤트 감지 -> Memstore 데이터 -> HFile(HDFS상 파일) flush
https://www.joinc.co.kr/w/man/12/hadoop/hbase/about - ...
- Compaction 방식
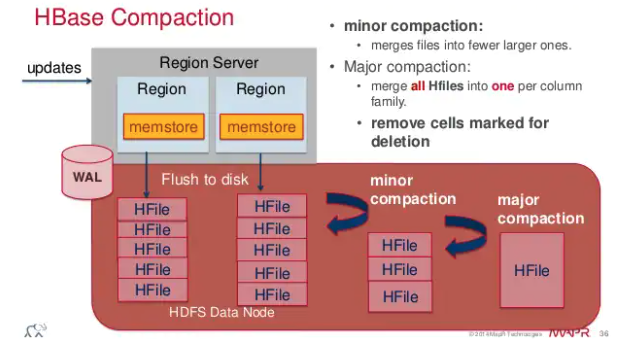
- 마이너 : 작은 HFile 들을 -> (병합) -> 큰 HFile 으로 (삭제된Row, 오래된 버전 데이터도 그대로 merge 대상이 됨)
- 특정 기준 (최대/최소 HFile 갯수 및 최대/최소 크기) 설정에 따라 이루어 짐.
- HFile 기본 블록 크기 : 64KB (작으면 랜덤접근, 크면 순차접근에 유리함)
- 메이저 : 저장소의 모든 HFile 들을 -> (병합) -> 하나의 HFile 생성 (삭제된Row, 오래된 버전 데이터는 제거됨)
- 장애복구 방식
- HMaster 가 장애 감지 -> 해당 노드의 Region 을 -> 타 RegionServer 가 대체 시킴.
- 타 RegionServer 는 -> WAL 을 읽고 -> 해당 Region 의 Memstore 를 복구 함.
- HMaster 는 -> Meta Region 정보를 수정 -> 해당 Region 관한 서비스 재개.
- 해당 Region 데이터는 HDFS 에 의해 다시 복제까지 마무리 함.
- 2) 특징
- Master/Slave 구조
- Master가 분산된 복제 데이터 사이의 Consistency 보장 해줌.
- Master에 "파티션(샤드?) 정보" 가 있기 때문에, Master 장애시... Availability 보장안됨. (HA구성으로 해결)
- "파티션(샤드?) 정보" 변경시, Master만 바꾸면 됨. (그래서 RowKey 정렬이 가능한것 ?!?!?!)
- 복제와 샤딩
- 샤딩 : CF 기반 NoSQL 을 기본적으로~ RowKey 기반 샤드를 구성함.
- 복제 : Cyclic Replication

- NameNode 가 Master (데이터 메타정보 저장)
- DataNode 가 Slave (복제 데이터 저장)
- ... ??? ...
- RowKey
- Hash-Table 아니다... 가 뭔말이지?

https://nesoy.github.io/articles/2019-10/Hbase-Key-Design - col1-col2-col3-col4 가 각각 모여서? 따로? 저장이 된다.
- RowKey 일부분의 값으로 Partial-Scan 이 가능 !!! ㅎㄷㄷ
- RowKey 를 Composite-Key 으로 잘 구성하면 됨!
- PK(c1,c2,c3,c4) 의 순서가 중요하다. (Tall-Narrow-Row)
- but, 순서상 c1없이 쿼리하면... Full-Scan 인것 같다.
- 그래서 Index Table를 직접 만들어 응용해도 된다.
- 자체적으로 secondary-index는 제공하지 않음. (추가 인덱스 및 join, grpby 등등은 피닉스 SQL 차원으로 해결!)
- RowKey 잘못잡으면 -> (한 서버에 wrtie 몰려... Region 스플릿) Hot Spot 위험이 난무하고, 성능이슈가 있음...
- RowKey 순으로 정렬이 되고, time 및 seq 데이터를 RowKey로 잡으면... Hot Spot 발생 (??? 왜 ???)
- 1) Sequential-Key : 연속적인 값은... (write 성능 때문에) RowKey 으로 안좋다고 함.
- 2) Composite-Key : 여러게의 값을 Mashing 하여 만든 RowKey
- 2-1) Salted-Key : Random + Seq 예) md5 + 일련번호
- 2-2) PromotedField-Key : ID + Seq 예) 상품코드 + 년월일
- 3) Random-Key : md5, sha-1, sha256, ... 아주 Hot Spot 회피성을 극대화;;; (sequential read 성능은 나빠짐)
- Hadoop 과 밀접하게(?) 통합
- 보통 HDFS 를 저장소로 이용하기 때문에, Map/Reduce 나 Hive, Tajo 등과 효과적인 통합을 할수있다는 기대감이 있음.
- 즉, 각 노드의 Region(영역) 단위로 분산 병렬 M/R 처리가 가능하고~ (타SDK 기반 비하여) 네트워크 전송비용을 아낄수있음.
- Master/Slave 구조
- 3) 실무
- 설치
- Oracle JDK : ...
- SSH : 노드간에 SSH 통신이 자유롭게 되도록 셋팅 해.
- ntpd : 서버들 간에 시간을 동기화.
- Hadoop : 다운로드 및 설치 및 설정 및 환경변수 및 ...
- Zookeeper : ...
- HBase : ...
- 명령어
- CREATE
- create {테이블명}, {CF명}, {CF명}, ...
- 예) create test, {NAME=>cf1, VERSION=>1, TTL=>86400, BLOOMFILTER, ... }, {...}, ...
- Column Family 옵션
- NAME : 해당 CF 이름
- BLOCKSIZE : 읽기 연산시 로딩되는 블록단위의 크기. (기본값 64KB)
- BLOOMFIL..:현재 Region에 정보를 저장하고 있는지? 통계적 알고리즘으로 확인 하기위한 정보. (조회속도 Up! But, mem bad)
- VERSION : 히스토리 Version 제공. (블록체인 Hyperledger에서 잘 활용한다고... ??? 뭐!있!쀍!)
- ...
- Column-Family 를 여러개 등록 할 수 있음.
- Column 을 추가할때는, 등록된 CF만 사용 할 수 있음.
- 한 Region에서 CF 단위로 HFile이 생성되, 적절히 잘 column을 모우고 나누어야~ Disk I/O 를 줄인다.
- PUT
- put {테이블명}, {rowid}, {CF명:col명}, 값
- 예) put test, key1, cf1:age, 26 // "test" 테이블의 "key1" row에 "cf1:age" 값을 26 살으로 저장.
- ...
- SCAN
- HBase는 필터링이 강력하다는게 큰 장점으로 꼽힌다.
- https://www.cloudera.com/documentation/enterprise/latest/topics/admin_hbase_filtering.html
- (index 타는지? full-scan인지? 잘 판단해서 사용하면 됨.)
- scan {테이블명}, {옵션}
- 예) scan 'test' {COLUMN=>'cf1:nick', FILTER=>"ValueFilter(=,'substring:abc')"}
- 예) scan 'test' {COLUMN=>['cf1:age','cf1:nick'], LIMIT=>10, STARTROW=>'key1'}

- ...
- HBase는 필터링이 강력하다는게 큰 장점으로 꼽힌다.
- CREATE
- 설치
- ...
- 4) Apache Phoenix
- HBase 에서 SQL를 사용할수있게 하는, 하둡 에코시스템. (HBase의 클라이언트로 작동)
- secondary-index, join, group by, subquery, sequence, array, dynamic-column, paging 등 지원
- (HBase에서 지원하는게 아니라... 피닉스에서 Application-Side Logic으로써, 위 기능을 해주는것!!!)
- 예) secondary-index를 만들면, 피닉스가 내부적으로 table를 따로 만들어서~ 알아서 관리해주는것.
- 예) join 하면, 피닉스가 데이터를 다 가지고와서~ 해주는것. 그래서 제약이 있고, 성능이 안좋음.
- https://phoenix.apache.org/secondary_indexing.html
- ...
-끝-