
- AI : 사람의 지적능력을 구현한 기술
- Machine-learning : 데이터를 기반으로 모델 알고리즘을 학습 -> input 에 해당하는 output 을 추론하는 기술
- Deep-learning (Artificial Neural Network) : 인공 신경 회로망을 활용하는 머신러닝 기술
- Machine-learning : 데이터를 기반으로 모델 알고리즘을 학습 -> input 에 해당하는 output 을 추론하는 기술
- 역사
- 1차 AI (1960년대)
- '퍼셉트론' 개념 제시.
- 인간의 뉴럴을 따라해서, 특정 Input 의 활성이 on/off 되는 메커니즘.
- (1, x1, x2, ... x) * (w0, w1, w2, ... w) -> 입력함수 -> 활성화함수 -> Ouput
- 선형적인(?) 즉, 맞다 틀리다가 명확한 문제만 풀수있는 한계가 있음!
- 2차 AI (1980년대)
- 제프리 힌튼 : '다층 퍼셉트론' 과 '역전파 알고리즘' 을 발명됨.
- 판사같은 전문직을 대체할 시스템 (?) 으로 많은 투자를 받았지만... 대실패!
- (다층 구조상 앞단의 내용을 점점 까먹는 현상과 결국엔 if 문 덩어리가 되어버림)
- 3차 AI (2010 년대)
- 컴퓨터의 발전, 인터넷의 엄청난 데이터들 등등에 환경이 좋아짐.
- 제프리 힌튼 : Vanishing Gradient 문제를 해소할수있는 개선된 알고리즘을 다시 개발.
- ILSVRD 콘테스트에서~ 지금까지의 페러다임을 바꿈. (Shallow < AlexNet < ZFNet < VGG <ResNet < ... )
- 구글의 알파고 마케팅으로 전세계를 딥러닝이 강타함!
- 1차 AI (1960년대)
- 서비스 라이프 사이클

- 전통적인 ML 은 (번호판 인식처럼) 제한된 영역을 단순한 '피처엔지니러링' 할때 유리한데...
- DL 의 '인공 신경 회로망' 은 기본적으로 양질의 데이터가 아주 필요하다.
- 그 결과 유동적이고, 복합적인 문제도 잘 풀수있다.
- 1) 판단모델
- 기 수많은 다양한 데이터들이 각가 어떤 종류인지? 판단함.
- 학습과 패턴
- 지도학습 : 데이터(문제) 와 그 라벨|GroundTruth(정답) 을 함께 제공하여, 각별 패턴을 학습하는 방법.
- 이상탐지, Text, Image, Audio, Video 등등등 인식, ...
- 비지도학습 : 데이터(문제) 만 제공하여, 스스로 패턴을 찾아 클러스터링 하는 방법.
- 추천시스템, 타켓팅시스템, ...
- (번외) 강화학습 : 최소한의 행동으로 최대한의 보상을 얻을수있는 방향을 찾는 방법.
- (에이전트 -> 행동 -> 환경 -> 보상)
- 특정한 게임 Env에서 Action 결과로 발생한 Reward를 누적적으로 수치화.
- 알파고, 벽돌깨기, ...
- 지도학습 : 데이터(문제) 와 그 라벨|GroundTruth(정답) 을 함께 제공하여, 각별 패턴을 학습하는 방법.
- 2) 생성모델
- 새로운 데이터를 생성함.
- 주요 주제
- "거대한 모델" : ex) gpt3 = 몇천억개의 파라미터로 구성이 됨.
- "엄청난수의 데이터셋" : ex) DALL-E = 3억 개의 Img-Txt 데이터셋. (즉, img 와 txt 의 벡터?상관관계 파악)
- "프롬프트 엔지니어링" : Step By Step 어떻게 명령어를 구성해야 좋을지 ...
- 3) 학습방법
- 개념
- 모델 = 레이어들의 전체 합 (input layer -> [ hidden layers ] -> output layer)
- 노드 = 이동할때, 일정한 w를 곱하고~ 활성함수를 적용함.
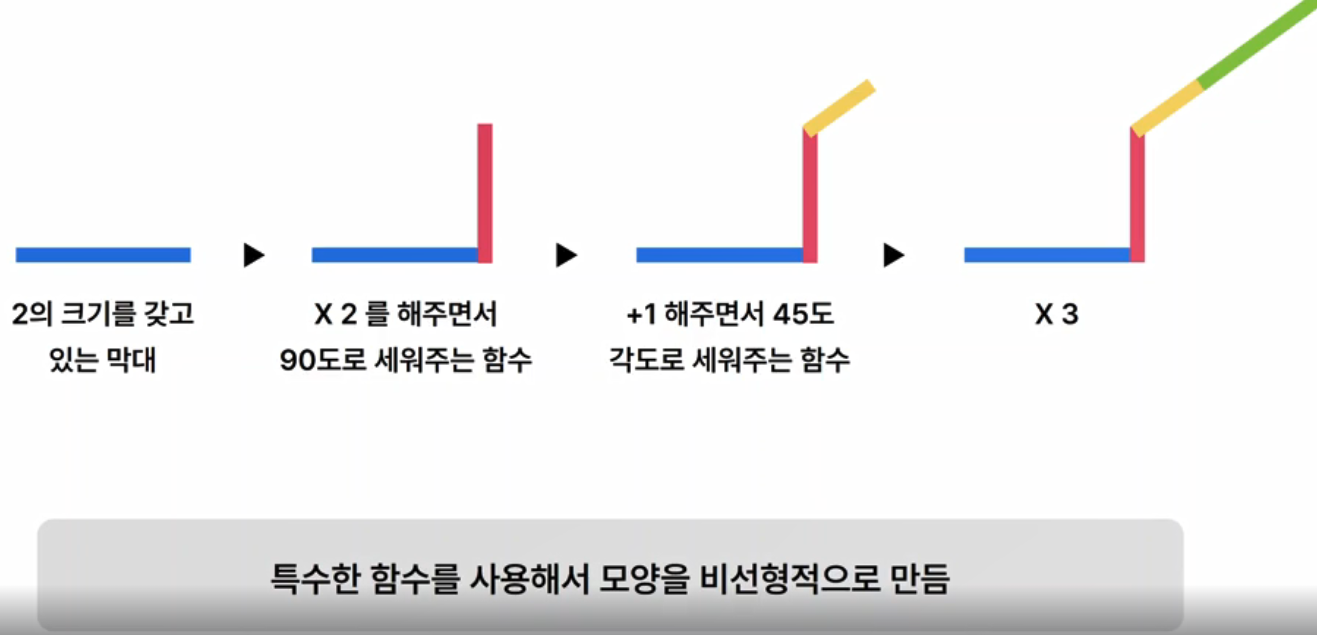
- 활성함수 = 퍼셉트론의 선형성을 -> 비선형적으로 만들어 주기위함!!!
- 파라미터 : 학습에서 산출되는 값. (weight coefficient, SVM의 벡터, 선형회귀의 결정계수, bias)
- 하이퍼 파라미터 : 학습으로 셋팅되는 값. (에폭, 학습률, 코스트, K개수)
- 모델 = 레이어들의 전체 합 (input layer -> [ hidden layers ] -> output layer)
- 1.순전파 : input -> 모든 노드의 가중치 및 활성함수 를 연산하여 -> output 을 예측값을 추론하는 과정.
- 2.Loss계산 : 예측값과 정답의 오차를 판단할 손실(Loss) 함수를 정의하고 계산하는 과정. (MSE, RMSE, ...)
- 3.역전파 : 각 가중치 w가 output 에 얼마나 영향을 끼쳤는지? 파악하여, 손실(Loss)을 줄이는 방향으로 업데이트!
- 수학적으론, 도함수 및 편미분의 개념이 필요함.

- 지역 최솟값 문제 :
- 모든 각 가중치 w를 업데이트하는 과정에서, 가장 낮은 손실(Loss) 지점을 어떻게 찾을수 있을지!
- Optimizer : 어떻한 방식으로 업데이트를 반복할지? 결정하는 알고리즘.
- Learning-rate : 가중치를 얼만큼씩 갱신해가면서 학습 할지? (촘촘히 할지? 크게크게 할지? 학습속도)

- 예) 최소값을 하나 발견하면, 그 이후엔 Learning-rate 를 늘려서~ 크게크게 몇번더 탐색하는 전략
- 하이퍼 파라미터 튜닝 : 몇 epoch 을 돌릴지? batch-size? 어떤 Optimizer 로 얼마의 Learning-rate? 등
- 개념
- 4) 이미지 처리
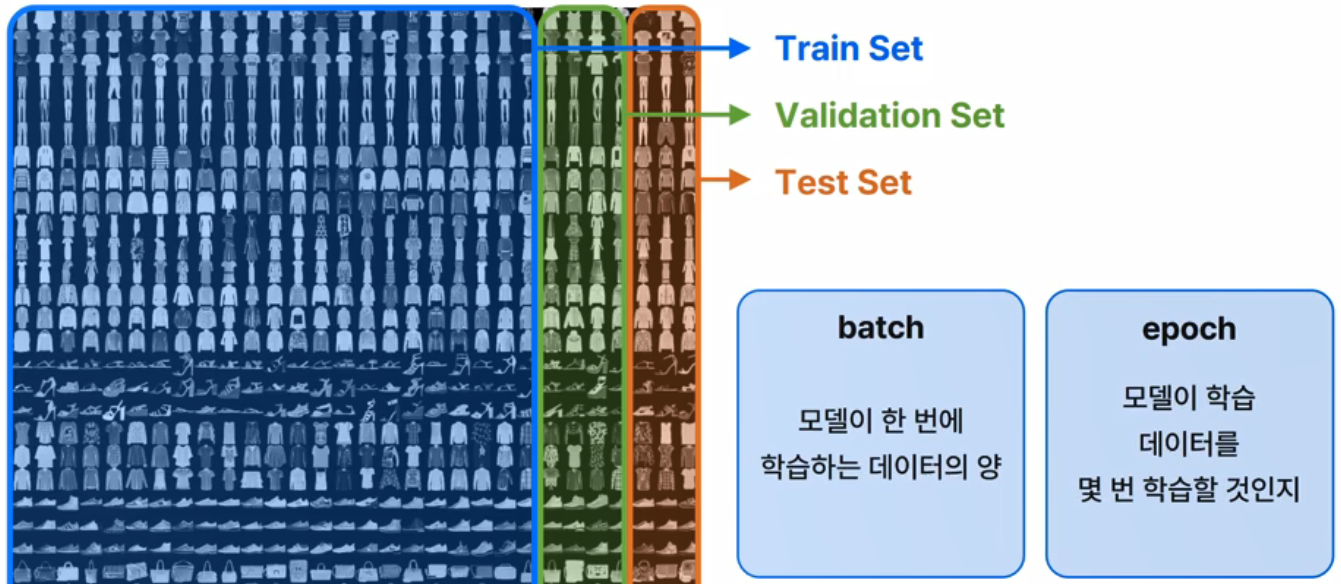
- 예) "이미지-카테고리" 쌍의 데이터
- Train Set 을 batch-size 만큼 단위로 랜덤하게 샘플하여 학습 -> 데이터셋 다 보면 -> 1-epoch 완료
- 1-epoch 완료 -> Validation Set 으로 중간평가 -> n- epoch 반복
- 최종 네트워크 완성 -> Test Set 으로 최종평가
-
dataset = pandas.read_csv(f"FashionMNIST.csv") fashion_category = {0: 't-shirt', ... } dataset_train, dataset_test = train_test_split(dataset, size=, shuffle=, random=) class TrainDataset(Dataset) self.fashion_category = numpy.asarray(fashion_category) self.fashion_image = numpy.asarray(fashion_image).reshape().astype('float32') ... class TestsDataset(Dataset) self.fashion_category = numpy.asarray(fashion_category) self.fashion_image = numpy.asarray(fashion_image).reshape().astype('float32') ... transform = transforms.Compose([ transforms.ToTensor() # 픽셀값 을 -> '텐서' 라는 형태로 바꾸어야 딥러닝 모델에 들어감! transforms.Normalize(0.5, 0.5) # 이미지 정규화(?) ]) trainset = TrainDataset(dataset_train, transform=transform) train_loader = DataLoader(dataset=trainset, batch_size=, shuffle=) validset = TestsDataset(dataset_test, transform=transform) valid_loader = DataLoader(dataset=validset, batch_size=, shuffle=) testset = TestsDataset(dataset_test, transform=transform) test_loader = DataLoader(dataset=testset, batch_size=, shuffle=) # 네트워크 설계 class FCNet(nn.Module): self.fc1 = nn.Linear(784, 128) # 784 개의 흑백픽셀 self.fc2 = nn.Linear(128, 64) # -> 히든128 -> 히든64 -> self.fc3 = nn.Linear(64, 10) # 10 개의 카테고리 def forward(x) x = x.float() h1 = F.relu(self.fc1(x.view(-1, 784))) # 활성함수 h1 = F.relu(self.fc2(h1)) # 활성함수 h1 = self.fc3(h2) return F.log_softmax(h3, dim=1) # 활성함수 def train() # 에폭을 반복하는 루프 ... return model def test(model_path) # 테스트 이미지들을 불러와 모델이 넣어 결과출력 ... return train(FCNet, '/model.pf') test('/model.pf')
- 4) CNN (이미지 특화 모델)
- Convolutional Neural Network
- 합성곱 (하나의 함수 x 다른 함수 반전 이동값 -> 구간에 대한 적분) 연산을 사용하는 신경망.
- 이미지 픽셀을 배열로 해체시키면, 이미지 특성이 깨짐 -> 이미지 특징을 유지한채로 압축!

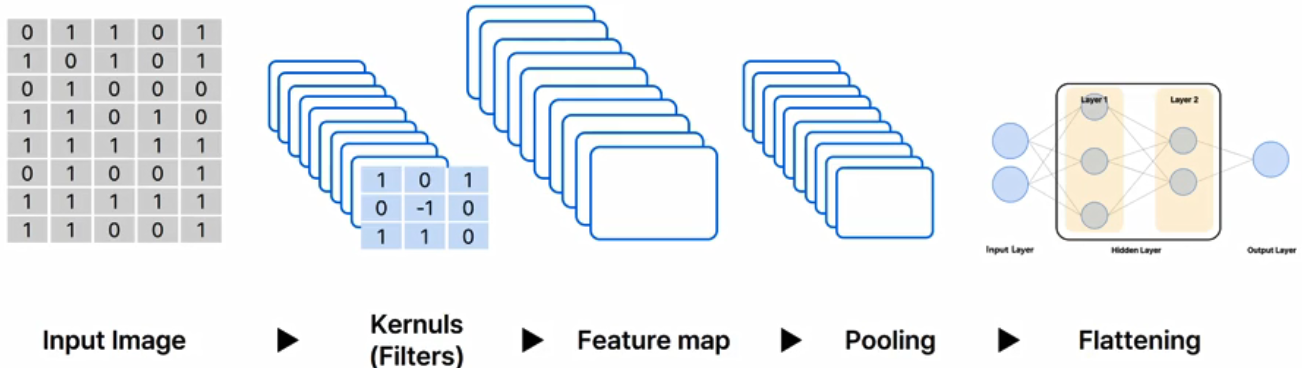
- 원본 -> 커널 -> 피처맵 -> 풀링(위치 변화에 더 강건해지도록) -> 모델

- 응용 Tasks
- 1. 이미지 분류
- 2. 물체 탐지
- 3. 이미지 분할
- 5) 자연어 처리

- ex) 'iam' -> 원핫인코딩 -> array[단어수][단어수] -> ...
- 5) RNN (순서를 기억하는것에 초점을둔 자연어 or 시계열 특화 모델)
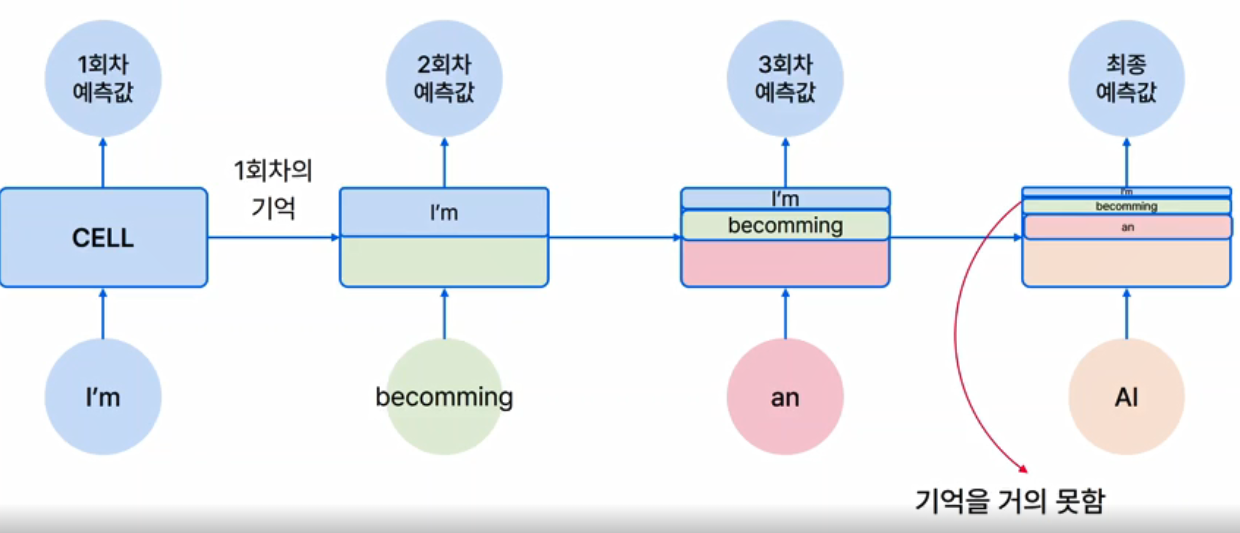
- Recurrent Neural Network
- 순환 (입력&출력의 시퀀스 단위) 처리를 하는 신경망.
- 입력값 -> Cell -> 예측값
- |_ ... <--/ (1,2...n 결과를 다시 누적적으로 Cell에 넣음)
- long term dependency problem
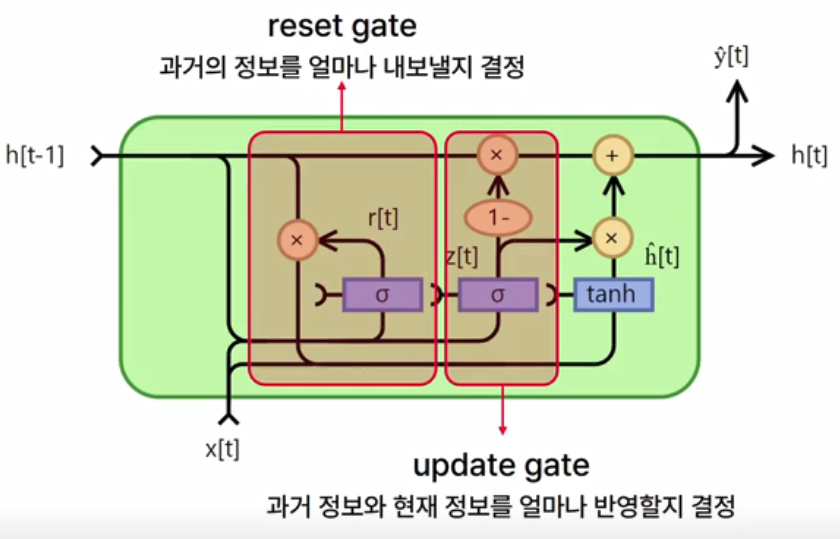
- 5) LSTM, GRU (이전 기억을 저장하는 식으로...)
- Long Short Term Memory
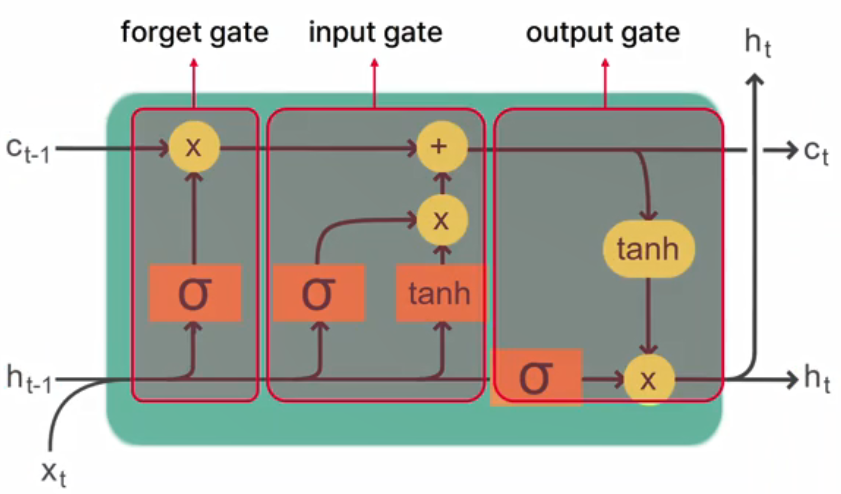
- Gated Recurrent Unit
- 6) 이미지 심화 (HuggingFace :Stable Diffusion)

- 스테이블 디퓨젼 불러오기
- ex)
- from diffusers import StableDiffusionPipeline
- MODEL_ID = 'ComoVis/stable-diffusion-v1-4'
- device = 'cuda'
- pipe = StableDiffusionPipeline.from_pretrained( ... )
- 전처리 및 추가 학습 -> ...
- 6) 자연어 심화 (HuggingFace : BERT)
- huggingface -> datasets -> 검색 (예: klue) -> "기계독해(mrc), 뉴스분류(ynat), 등등 제공"
- 사전학습 모델 불러오기
- ex)
- MODEL_NAME = 'bert-base-multilingual-cased'
- tokenizer = AutoTokenizer.from_pretrained( MODEL_NAME)
- model = AutoModelForQuestionAnswering. from_pretrained( MODEL_NAME)
- 전처리 및 추가 학습 -> ...

-끝-
'IT 서적 & 강좌' 카테고리의 다른 글
| [웨비나] AWS AI/ML 스페셜 (0) | 2022.08.30 |
|---|---|
| [세미나] 테크 블로그 만들기 (0) | 2022.03.20 |
| [웨비나] Container Immersion Day (4/8 EKS) (0) | 2021.04.08 |
| [웨비나] Container Immersion Day (4/8 K8S) (0) | 2021.04.08 |
| [웨비나] Container Immersion Day (4/7 ECS) (0) | 2021.04.07 |